

CSCI 3325
Distributed Systems
Fall 2023
Instructor: Sean Barker
| Release Date: | Thursday, September 28. |
| Acceptance Deadline: | Monday, October 2, 11:59 pm. |
| Due Date: | Friday, October 20, 11:59 pm. |
| Collaboration Policy: | Level 1 |
| Group Policy: | Groups of 2 or 3 |
In this project, you will design and implement a multi-tier distributed system using remote procedure calls (RPCs) as the core distributed programming model. You will also experiment with your system to see how query loads affect performance.
This project should be done in teams of two or three (unless otherwise cleared with me). As in Project 1, all team members are expected to work on all parts of the project.
You have been tasked to design Nile.com: the world's smallest online bookstore. Since Nile.com plans to one day overtake Amazon, you will need to follow sound design principles in building the online store to allow for future growth.
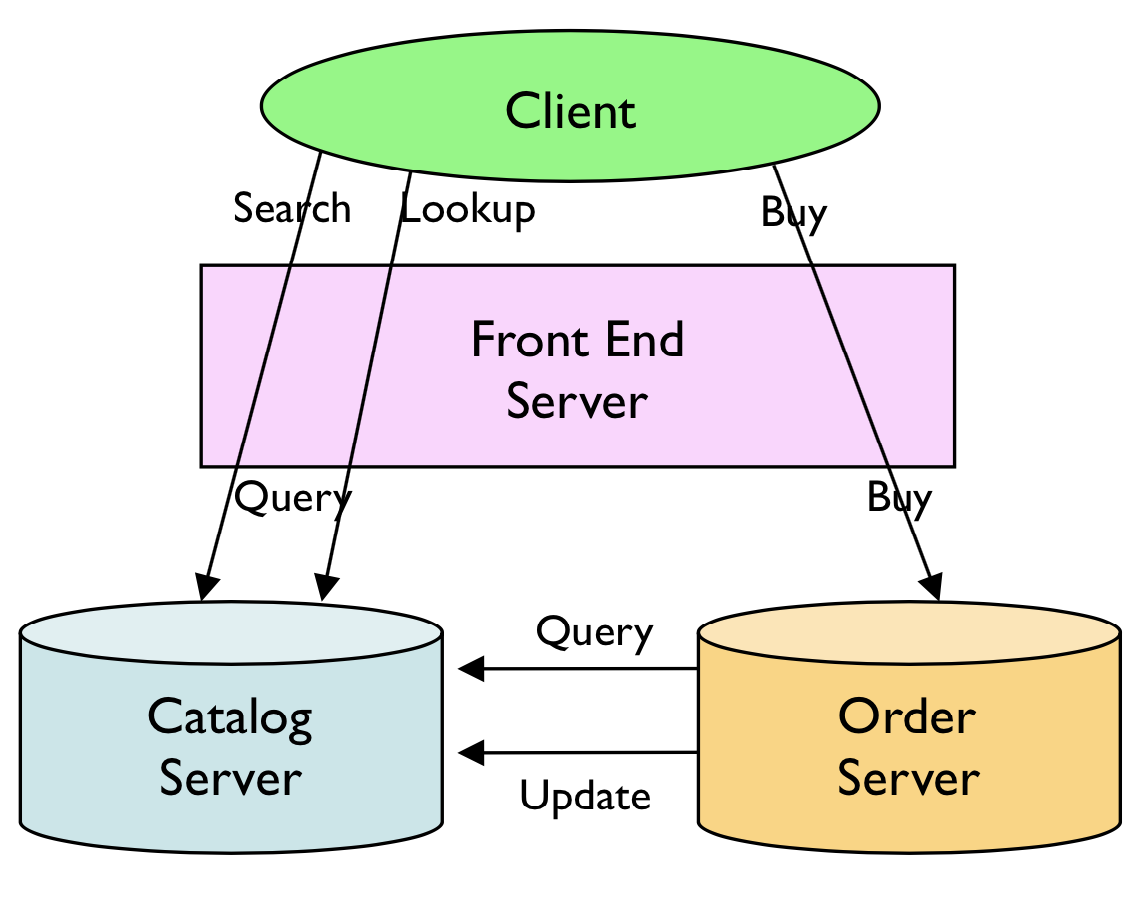
The architecture of the system is illustrated in the figure below. The store will employ a two tier design consisting of a front-end and a back-end. The front-end server will accept user requests (i.e., communicate with clients) and perform initial processing. The backend consists of two components: a catalog server and an order server. The catalog server maintains information on current inventory, while the order server is responsible for keeping the catalog appropriately updated.
Bookstore inventory is tracked within the system as a series of book entries, where each book entry consists of the following:
The various components of the system will interact with the inventory via the operations detailed below.
The front end server should support three operations (which are invoked by clients):
search(topic) – return all item numbers belonging to a specified topic (i.e., category)lookup(item_number) – look up inventory details (name, topic, and inventory count) for a particular itembuy(item_number) – purchase one copy of a particular item, removing it from future inventory
The search and lookup operations trigger queries to the catalog server, while the buy operation triggers a request to the order server.
The catalog server should support two operations:
query(arg) – lookup details of current inventory. Two types of queries should be supported: query-by-subject and query-by-item. In the first case, a topic is specified and the server returns all matching entries. In the second case, an item number is specified and all relevant details are returned.update(item_number, qty) – update the current inventory of a given item by adding the specified quantity (which may be positive or negative).The order server should support a single operation:
buy(item_number) –
verify that the item is in stock by querying the catalog server, then decrement the number of items in stock by one. The buy request can fail if the item is out of stock.Initial inventory stock may be determined arbitrarily. New stock should arrive automatically and periodically (e.g., every 30 seconds a new copy of each book is added; the details of this are up to you). The actual set of books and topics contained in the catalog is also up to you. While your design and data structures should be flexible enough to handle any catalog, the objective here is not to actually manage a large dataset, so a small number of books (e.g., 10 books spread over 3 topics) is sufficient. In a real service, the catalog would likely be stored in a full-fledged database server or similar. Here, you do not need to store the catalog on disk at all; keeping the catalog data as an in-memory data structure in the catalog server is fine.
All servers should be written in Java using XML-RPC for remote communication. In addition to the three server programs, you will write two clients: one in Java and one in Python. Both clients should communicate with the same Java front-end server program using XML-RPC.
No GUIs are required for any servers or clients. Simple command line interfaces are fine (e.g., for issuing requests via a client). The exact format of the client interface is up to you, but should include typical information and operate in an intuitive way. For instance, you should be able to see the results in a query in a cleanly formatted manner and should be able to tell whether purchase requests succeeded or failed.
The service must support multiple concurrent queries; i.e., mutliple clients should be able to have their queries serviced without having to wait for other queries to complete first. In contrast, purchases do not need to support concurrency; while multiple clients may of course issue purchase requests simultaneously, the order server does not need to actually perform them concurrently.
Be aware of thread synchronization issues to avoid inconsistency or errors in your system. For instance, two concurrent purchase requests should not both be able to buy a single remaining copy of a book. You may find Java's synchronization primitives helpful here (described more below).
Some of the programs will need to be given one or more hostnames when started in order to connect to the rest of the system. These hostnames should be provided as command-line arguments to your programs. In particular:
Note that the above dictates the order in which the system should be launched: the catalog server first, then the order server, then the front-end server, and finally one or more clients.
To help you get started with XML-RPC, an example server and two clients are provided below (which are also included in the starter code):
As a place to start, try running the server and clients on the class server and make sure you understand the basic structure of the code.
To compile your Java files, you will need to include the Apache XML-RPC Java classes in your "classpath", which is basically the set of directories that Java uses to search for included classes. To make things easier for you, the starter code includes a functional Makefile that will invoke javac with the right classpath arguments to compile your code. The starter code includes Java files for the three server programs and the client program, as well as a Python skeleton for the second client. You will likely need to write additional Java classes, but you should not need to write any other classes containing main methods that will be executed directly.
While the Makefile will take care of the classpath when compiling with javac, you also need to specify the classpath when executing the code with java. There are two ways to do this. The simple but cumbersome method is to specify the classpath as a command-line argument every time you run your code, such as below (all on one line, and the same for every class except for the class name to execute):
A better option is to set your classpath by adding the following line to your .bashrc file (note the leading period) in your home directory on the class server (use this exact text, which should all be on one line):
Once you've done this, every new shell process will have the classpath automatically set up, and you should be able to run your code using java without having to specify the classpath.
If you want to develop in Java on your local machine, you may need to download the XML-RPC classes. You will need to add the jarfiles to your local or IDE classpath in order to use them (but note that the paths may be different from those specified in the provided Makefile).
Documentation on the XML-RPC classes (e.g. Javadoc) is available on the Apache XML-RPC site.
XML-RPC is an example of a stateless protocol, which means that no information (or state) is automatically maintained across multiple communication calls. In other words, every XML-RPC request completely stands alone and is not intrinsically related to any other request. Other examples of stateless protocols include HTTP and IP. In contrast, protocols like TCP are stateful, in which information must be tracked across messages as part of the protocol (since TCP messages are inherently part of a stream of messages between two processes).
The main practical implication of the statelessness of XML-RPC is that the server will create a new server object (e.g., an instance of the Server class in the example code) for every new RPC request. This approach simplifies XML-RPC itself and makes it easy to handle lots of simultaneous requests, but may complicate your program design a bit to accommodate this. You can see the impact of statelessness yourself by adding an instance variable to the Server class, modifying it and printing it out within the RPC, then making mulitple requests to the server.
For more details and an example of the new object creation issue discussed above, see this XML-RPC reference page.
Your servers will need to be careful about protecting data that may be accessed by multiple requests concurrenctly. In Java, a standard way to perform synchronization is via the synchronized keyword, which allows you to mark specific methods as only safe for execution by one thread at a time. Doing so ensures that the method will not be executed concurrently, which is good for safety but potentially bad for performance. Thus, the essential challenge of synchronization is to provide safety when necessary but still allow for enough parallelism to achieve good performance.
One specific note here: marking your server methods synchronized will not actually accomplish much, since Apache XML-RPC creates a new instance of the server class on each RPC call. As a result, simultaneous calls to the server be acting on different objects, and thus marking them synchronized will not prevent them from running concurrently. Instead, you should synchronize on something that will be shared between requests; this might be a shared data structure, or a class-level lock created expressly for this purpose. See this page for an example of using a class-level lock.
You may also find Oracle's tutorial on synchronization in Java useful if you have not done much concurrent programming previously.
For initial testing, you can run all components of the system on the same physical machine. For later testing, you will be provided a set of 4 separate machines for running each component of the system separately - details on these machines will be provided later. You will need to run a set of performance experiments and provide results in your writeup (described below).
Similar to Project 1, you will write a README describing important aspects of your project. You will also need to run some experiments and detail the results of those experiments in your writeup.
Your writeup should contain your names and the following sections:
fig1.png) and then referenced from your README document.A good rule of thumb for running real-world experiments is to be skeptical of the results; what might explain the results you see, even if they weren't necessarily what you expected? Note that this isn't to say that you should necessarily expect to be surprised by your results, but it is almost always the case that real-world experiments don't perfectly demonstrate what we expect (even if the underlying principle you're trying to demonstrate is sound). If you don't find that your results don't demonstrate what you expected, explain why you think that might be.
As usual, the link to initialize your repository on GitHub will be posted to Slack. You can initially work on the class server, then move over to the multiple other machines to be provided (particularly for the purpose of running experiments).
Your program will be graded on (1) correctly implementing the server specification, (2) the design and style of your program, and (3) the quality of your writeup. For guidance on what constitutes good design and style, see the Coding Design & Style Guide, which lists many common things to look for. Please ask if you have any other questions about design or style issues.