 |
CSCI 3325 Spring 2015 Instructor: Sean Barker |
 |
|
CSCI 3325 Spring 2015 Instructor: Sean Barker |
|
The previous three assignments have given you experience with single-tier client/server systems, multi-tier client/server systems, and cluster-based systems. The purpose of your fourth and final project is to give you experience with computing in the wide-area, as well as designing a more complex distributed system that will run on many machines.
Your final project should be done in teams of two or three.
Like in project 3, we will continue to use a set of virtual machines provisioned through Amazon EC2 for you to run your applications. The infrastructure is different from project 3 in several key ways, however: (1) all machines are shared, rather than dedicated to your group, (2) machines are no longer geographically in the same area, but rather are spread around the world, and (3) you will have access to ~30 machines, and should be aiming to run your system on as many of them as possible. Some of these machines may not be entirely reliable, or may have slower network connections, etc! This is part of the challenge of operating in the wide-area.
Since these machines are shared, you do not have sudo permissions on these machines. If you need specific software installed, please let me know and I can install it for you. Also, please be good citizens whenever possible! While some degree of interference is inevitable, you should not try to max out all the machines transferring data at full speed for long periods at a time. This will make your classmates unhappy.
The guidelines for your final project are much more open-ended than for the previous projects. Creativity is encouraged! However, you should be aiming for running on at least ~20 machines, and you should aim to provide robust fault-tolerance and scalability in your system (to the extent possible, given the architecture of your system). Remember that system design is all about tradeoffs (e.g., performance vs fault tolerance, complexity vs scalability), and you are almost certainly going to need to make compromises. The key point is to be conscious of what these compromises are!
If you are struggling to come up with a project idea, a suggested project is to build a simple peer-to-peer file transfer application. In such an application, the basic idea is that a peer that wishes to download a particular file can download it simultaneously from all peers that have at least part of the file. Thus, a group of peers can distribute the file more rapidly than if a single server had to send the file in its entirety to a number of clients that want to download the file. The figure below shows this basic design (in which peers exchange 'chunks' of the file with each other).
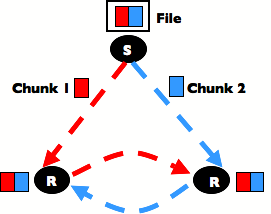
Note that even if you choose to pursue this suggested project idea, there is still room for creativity! For example, questions that you might consider in the design of your system include (a) how do peers organize the connections between them, (b) how do peers locate a file that they wish to download, or (c) how do peers decide what chunks to download (and who to download from).
Regardless of whether you choose your own project or opt for the suggested project above, it is important you actively manage the complexity of your system, especially at first. It is much better to start with a simple design, implement it, then add features later, rather than starting with an overly complex design and never getting a working prototype! Ideally, you should start with a base 'core' of the system that you are sure you can implement, then a set of extensions that you can add once the base system is running.
Additionally, it is important to decide what metric(s) you are optimizing for when you build your system. For example, are you trying to minimize transfer time, aggregate bandwidth, or something else? Make sure you discuss these decisions in your writeup.
The technology you choose to use in your system is up to you. While you are welcome to use any of the technologies that we have already used or discussed in the semester to implement your system (e.g., Java RMI, XML-RPC in one of the many languages that supports it, C sockets, etc), you are not restricted to any particular language or communication framework. However, if you are using something that we have not discussed, you should clear it with me first.
One of the challenges of this assignment is managing and running a distributed application without an off-the-shelf control infrastructure (ala MapReduce). Don't try to run your system on 20 machines by opening up 20 terminal windows! Instead, it is strongly recommended that you automate the process of deploying and running your application through scripts whenever possible. Every systems programmer should be proficient in at least one scripting language (e.g., Bash, Python, Perl), and this wiill save you lots of time trying to run your system. E.g., rather than SSHing to 20 machines and issuing the same command one-by-one, just write a script that automatically issues the command over SSH to all the machines you're trying to run on! Keep in mind the principle of DRY (don't repeat yourself).
Of course, initially you will be better served by just running on a few machines during development, and then scaling up to more machines once your system is running.
You are welcome to use the CSCI 3325 development server while implementing your system. For instance, you might choose to develop your application on the class server, and run scripts from there to deploy and run your system on the Amazon servers.
In addition to building the system itself, you will write a paper detailing and evaluating your system, as well as present your project to the class at the end of the semester as detailed below.
To submit your assignment, submit a gzipped tarball to Blackboard. Please include the following files in your tarball by May 16 at 5pm:
| Last modified: Jan 02, 2019 | Course Home • Schedule • Projects • Feedback [on-campus] |   |